Содержание
- Место MPI в иерархии средств параллельного программирования
- Правила работы с MPI
- Нетривиальные решения некоторых типовых задач, стоящих перед системой связи:
- Чего нет в MPI, но будет в MPI-2
- Сравнение с PVM
- Сравнение с SHM
- Какое программное обеспечение существует между программистом и MPI
- Рекомендуемые источники информации по MPI
- Версии документа
Место MPI в иерархии средств
параллельного программирования
Создание параллельной программы включает в себя две основных стадии:- последовательный алгоритм подвергается декомпозиции (распараллеливанию), т.е. разбивается на независимо работающие ветви; для взаимодействия в ветви вводятся две дополнительных нематематических операции: прием и передача данных.
- распараллеленный алгоритм записывается в виде программы, в которой операции приема и передачи записываются в терминах конкретной системы связи между ветвями.
С точки же зрения программиста базовых методик работы (или, как нынче принято говорить, парадигм) две - данные могут передаваться:
- через разделяемую память, синхронизация доступа ветвей к такой памяти происходит посредством семафоров,
- в виде сообщений.
- разделяемая память на не-SMP-комплексах - посредством организации единого виртуального адресного пространства на изолированных друг от друга физических ОЗУ; такая имитация аппаратными средствами нередко применяется на NUMA-машинах;
- на SMP-машине вырожденным каналом связи для передачи сообщений служит разделяемая память.
Таким образом, можно считать назревшей потребность в стандарте на интерфейс программиста, который бы сделал создание параллельных приложений таким же:
- мобильным,
- эффективным,
- надежным,
| Параллельное приложение | ||
| Средства быстрой разработки приложений (RAD) Распараллеливающие препроцессоры | ||
M P I | ||
| разделяемая память и семафоры | индивидуальные интерфейсы с передачей сообщений | TCP/IP |
| SMP-машины | MPP-машины | сети |
Правила работы с MPI
MPI расшифровывается как Message Passing Interface - Интерфейс с передачей сообщений, т.е. конкретному стандарту присвоено название всего представляемого им класса программного инструментария. В его состав входят, как правило, два обязательных компонента:- библиотека программирования для языков Си, Си++ и Фортран,
- загрузчик исполняемых файлов.
Для MPI принято писать программу, содержащую код всех ветвей сразу. MPI-загрузчиком запускается указываемое количество экземпляров программы. Каждый экземпляр определяет свой порядковый номер в запущенном коллективе, и в зависимости от этого номера и размера коллектива выполняет ту или иную ветку алгоритма. Такая модель параллелизма называется Single program/Multiple data ( SPMD ), и является частным случаем модели Multiple instruction/Multiple data ( MIMD ). Каждая ветвь имеет пространство данных, полностью изолированное от других ветвей. Обмениваются данными ветви только в виде сообщений MPI.
Все ветви запускаются загрузчиком одновременно как процессы Юникса. Количество ветвей фиксировано - в ходе работы порождение новых ветвей невозможно. Если MPI-приложение запускается в сети, запускаемый файл приложения должен быть построен на каждой машине.
Ниже, в следующих трех разделах, будут вкратце рассмотрены некоторые функциональные возможности MPI, причем упор будет сделан не на том, что они делают (все аналоги MPI так или иначе делает то же самое), а на том, как они это делают, какие нетривиальные решения были найдены для выполнения типовых действий.
Функции пересылки данных
Хотя с теоретической точки зрения ветвям для организации обмена данными достаточно всего двух операций (прием и передача), на практике все обстоит гораздо сложнее. Одними только коммуникациями "точка-точка" (т.е. такими, в которых ровно один передающий процесс и ровно один принимающий) занимается порядка 40 функций. Пользуясь ими, программист имеет возможность выбрать:- Способ зацепления процессов - в случае неодновременного вызова двумя процессами парных функций приема и передачи могут быть произведены:
- Автоматический выбор одного из трех нижеприведенных вариантов;
- Буферизация на передающей стороне - функция передачи заводит временный буфер, копирует в него сообщение и возвращает управление вызвавшему процессу. Содержимое буфера будет передано в фоновом режиме;
- Ожидание на приемной стороне,
завершение с кодом ошибки на передающей стороне; - Ожидание на передающей стороне,
завершение с кодом ошибки на приемной стороне.
- Способ взаимодействия коммуникационного модуля MPI с вызывающим процессом:
- Блокирующий - управление вызывающему процессу возвращается только после того, как данные приняты или переданы (или скопированы во временный буфер);
- Неблокирующий - управление возвращается немедленно (т.е. процесс блокируется до завершения операции), и фактическая приемопередача происходит в фоне. Функция неблокирующего приема имеет дополнительный параметр типа "квитанция". Процесс не имеет права производить какие-либо действия с буфером сообщения, пока квитанция не будет "погашена";
- Персистентный - в отдельные функции выделены:
- создание "канала" для приема/передачи сообщения,
- инициация приема/передачи,
- закрытие канала.
Таким образом, MPI - весьма разветвленный инструментарий. Приведу цитату из раннего себя: "То, что в конкурирующих пакетах типа PVM реализовано одним-единственным способом, в MPI может быть сделано несколькими, про которые говорится: способ А прост в использовании, но не очень эффективен; способ Б сложнее, но эффективнее; а способ В сложнее и эффективнее при определенных условиях".
Замечание о разветвленности относится и к коллективным коммуникациям (при которых получателей и/или отправителей несколько): в PVM эта категория представлена одной функцией, в MPI - 9 функций 5 типов:
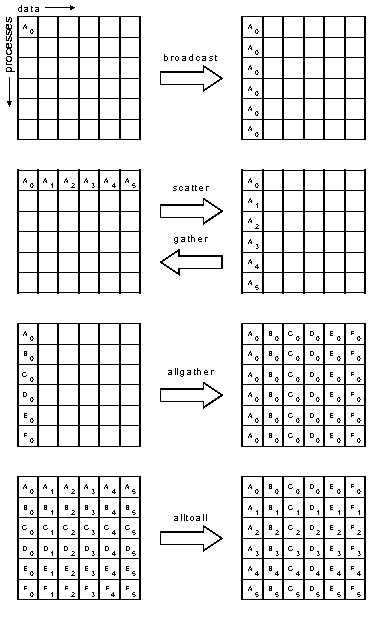{kind=link}
- broadcast: один-всем,
- scatter: один-каждому,
- gather: каждый-одному,
- allgather: все-каждому,
- alltoall: каждый-каждому.
if( myRank == 0 )
{
for( i=1; i < numLoops; i++ )
MPI_Send( ... , i, ... );
} else
MPI_Recv( ... , 0, ... );
... в то время, как имеющиеся в MPI функции оптимизированы - не пользуясь функциями "точка-точка", они напрямую (на что, согласно идеологии MPI, программа пользователя права не имеет) обращаются:- к разделяемой памяти и семафорам на SMP-машине, при этом происходит одно копирование в разделяемую память и numLoops-1копирований из нее просто функцией memcpy();
- к TCP/IP при работе в сети: в качестве адреса получателя при передаче используется т.н. "широковещательный", с "-1" в поле адреса машины.
Коллективы ветвей
В MPI хорошо продумано объединение ветвей в коллективы. В сущности, такое деление служит той же цели, что и введение идентификаторов для сообщений: помогает надежнее отличать сообщения друг от друга. В большинстве функций MPI имеется параметр типа "коммуникатор", который можно рассматривать как дескриптор (номер) коллектива. Он ограничивает область действия данной функции соответствующим коллективом. Коммуникатор коллектива, который включает в себя все ветви приложения, создается автоматически при старте и называется MPI_COMM_WORLD.Идентификаторы программист назначает сообщениям вручную, и существует вероятность, что вследствие его ошибки два разных сообщения получат одинаковые идентификаторы. Коллективы создаются функциями самого MPI, так, чтобы гарантированно избежать случайных совпадений.
В качестве идентификатора ожидаемого сообщения функции приема может быть передан т.н. "джокер" - принять первое пришедшее сообщение независимо от его идентификатора и/или отправителя. Такой вызов может по ошибке перехватывать и те сообщения, которые должны быть приняты и обработаны в другом месте ветви. Для коммуникаторов "джокера" не существует, поэтому работа разных функций через разные коммуникаторы гарантированно предохраняет их от взаимных краж информации: коммуникаторы являются несообщающимися сосудами.
Коммуникаторы, помимо собственного номера и состава входящих в них ветвей, хранят и другие данные. Например, кроме обязательной линейной нумерации, ветвям коллектива может быть дополнительно назначена нумерация картезианская или в виде произвольного графа - это может оказаться удобным для решения некоторых классов задач. Коллективу может быть назначена функция-обработчик ошибок взамен назначаемой по умолчанию. Пользуясь механизмом "атрибутов", для коллектива пользователь может завести набор совместно используемых его ветвями данных.
Зачем MPI знать о типах данных
О типах передаваемых данных MPI должен постольку-поскольку при работе в сетях на разных машинах данные могут иметь разную разрядность (например, тип int - 4 или 8 байт), ориентацию (младший байт располагается в ОЗУ первым на процессорах Intel, последним - на всех остальных), и представление (это, в первую очередь, относится к размерам мантиссы и экспоненты для вещественных чисел). Поэтому все функции приемопередачи в MPI оперируют не количеством передаваемых байт, а количеством ячеек, тип которых задается параметром функции, следующим за количеством: MPI_INTEGER, MPI_REAL и т.д. Это переменные типа MPI_Datatype (тип "описатель типов", каждая его переменная описывает для MPI один тип). Они имеются для каждого базового типа, имеющегося в используемом языке программирования.Однако, пользуясь базовыми описателями, можно передавать либо массивы, либо одиночные ячейки (как частный случай массива). А как передавать данные агрегатных типов, например, структуры? В MPI имеется механизм конструирования пользовательских описателей на базе уже имеющихся (как пользовательских, так и встроенных).
Более того, разработчики MPI создали механизм конструирования новых типов даже более универсальный, чем имеющийся в языке программирования. Действительно, во всех мне известных языках программирования ячейки внутри агрегатного типа (массива или структуры):
Выигрыш от использования механизма конструирования типов очевиден - лучше один раз вызвать функцию приемопередачи со сложным шаблоном, чем двадцать раз - с простыми.
Чего нет в MPI, но будет в MPI-2
В функциональности MPI есть пробелы, которые устранены в следующем проекте, MPI-2. Спецификация на MPI-2 уже выпущена в свет, а появление первых реализаций планируется в конце 1998 года. Вкратце перечислим наиболее важные нововведения:- Взаимодействие между приложениями. Поддержка механизма "клиент-сервер". Станет возможным писать на MPI не только расчетные математические задачи, но и системы массового обслуживания (базы данных и проч.).
- Динамическое порождение ветвей. Для программирования расчетных задач это не нужно (хотя многие по привычке хотели бы иметь в MPI аналоги fork() и spawn() ).
Действительно, не имеет смысла запускать ветвей больше чем... и нет особого вреда в том, чтобы запускать ветвей меньше, чем... реально имеется процессоров, не так ли? Процессор не станет работать в N раз быстрее, если вместо одной ветви на нем запустить N ветвей. И наоборот, ветвь, для которой не найдется работы, в "спящем" состоянии будет потреблять сущие крохи от процессорного времени.
Однако такая возможность однозначно необходима для написания системы массового обслуживания.
- Для работы с файлами создан архитектурно-независимый интерфейс. Это имеет значение, особенно если диск находится на одной ЭВМ, а ветвь, которая должна с ним работать - на другой. В отсутствие такого интерфейса пересылку данных приходится либо организовывать вручную, либо полагаться на сетевые возможности операционной системы (NFS, Parix и т.д.). По сравнению и с тем, и с другим, MPI гарантирует лучший баланс между универсальностью и быстродействием.
- Сделан шаг в сторону SMP-архитектуры. Теперь разделяемая память может быть не только каналом связи между ветвями, но и местом совместного хранения данных. Для этого ветви делегируют в MPI т.н. буфера-"окна". Интерфейс выполнен так, чтобы в-принципе его можно было реализовать и через передачу сообщений на не-SMP-комплексах. MPI автоматически поддерживает идентичность содержимого всех "окон" с одинаковым идентификатором.
Для этого механизма придуман термин "One-sided communications" ("односторонние коммуникации"), так как ветви-получателю не требуется явно вызывать функцию приема для получения новой информации; функция передачи в ветви-отправители осуществляет "Remote memory access" ("удаленный доступ к памяти", сокращенно RMA).
Правда, возникает вопрос: раз уж передача данных становится неявной, а синхронизация ветвей при доступе к "окнам" - явной, не станут ли возможными в MPI т.н. нестабильные ошибки, вызванные неправильной синхронизацией - бич программ, взаимодействующих через разделяемую память?
Сравнение с PVM
Сравнение необходимо, так как названия MPI и PVM часто упоминаются рядом.Итак, общие характеристики:
- одна и та же решаемая задача: обеспечение межпроцессовой связи,
- методика программирования: SPMD с передачей сообщений,
- методика использования: библиотека для Си/Фортрана + загрузчик,
- мобильность инструмента и, как следствие, мобильность создаваемых программ.
- интерфейс программиста проще и примитивнее,
- интерфейс пользователя сложнее и запутаннее,
- предусмотрено динамическое размножение ветвей (есть в MPI-2),
- возможно взаимодействие приложений, запущенных одним и тем же пользователем (есть в MPI-2),
- загрузчик приложений, создающий собственно Виртуальную Параллельную Машину, является постоянно запущенным (полезно для исследовательских целей); в отличие от MPI, где срок жизни загрузчика строго совпадает со сроком жизни одного конкретного приложения (более простое, надежное и компактное решение),
- PVM старше на 6 лет, но не продвигается производителями ЭВМ на роль единого стандарта.
Сравнение с SHM
Преимущества модели shared memory ( SHM ) по сравнению с MPI:- Модель программирования межпроцессных связей через общую память с синхронизацией семафорами - базовая для SMP- и однопроцессорных компьютеров. Функции работы с Shared memory непосредственно входят в состав каждой многозадачной операционной системы. В пределах одного компьютера все остальные средства межпроцессовой коммуникации реализуются через SHM, и потому заведомо являются менее быстрыми,
- В модели с общей памятью совместно используемые данные хранятся в такой памяти в единственном экземпляре, без создания локальных копий для каждой ветви приложения. Ветви, работающие с такими данными, затрачивают незначительное время на синхронизацию доступа к данным, и в-целом соотношение скорости коммуникаций и скорости вычислений в модели с общей памятью выше, чем в модели с передачей сообщений. Следовательно, класс задач, пригодных к распараллеливанию в SHM, в-принципе шире, нежели в MPI.
- SHM намного дольше используется для программирования высокопроизводительных вычислений, и многие проблемные программисты либо изучили эту методику лучше, либо вообще изучили только ее одну.
Итак, почему MPI не(намного) хуже SHM:
- в хорошо распараллеленном приложении на собственно взаимодействие между ветвями (пересылки данных и синхронизацию) тратится небольшая доля времени - несколько процентов от общего времени работы; таким образом, замедление пересылок, допустим, в два раза не означает общего падения производительности вдвое - она понизится на несколько процентов; подобное незначительное понижение производительности можно считать приемлемым,
- средства, имеющиеся в MPI (асинхронные/перманентные коммуникации) и особенно в MPI-2 (удаленный доступ к памяти) предоставляют скорость, сравнимую со скоростью SHM.
- все имеющиеся реализации SHM API либо в-принципе непереносимы за пределы SMP-машин, либо недостаточно эффективны, либо недостаточно распространены;
- стоимость вычислений и коммуникаций в SMP-машинах падает медленнее, чем в MPP-комплексах и сетях;
- методика обмена данными в виде сообщений обладает изначально большей наглядностью для программиста,
- в отличие от MPI, SHM API, как правило, реализует только самые базовые операции,
- MPI сокращает разрыв в скорости выполнения программ, и увеличивает разрыв в скорости их написания.
Какое программное обеспечение существует
между программистом и MPI
MPI сам по себе является средством:- сложным: спецификация на MPI-1 содержит 300 страниц, на MPI-2 - еще 500 (причем это только отличия и добавления к MPI-1), и программисту для эффективной работы так или иначе придется с ними ознакомиться, помнить о наличии нескольких сотен функций, и о тонкостях их применения;
- специализированным: это система связи - и все.Кстати, можно сказать, что сложность (т.е. многочисленность функций и обилие аргументов у большинства из них) является ценой за компромисс между эффективностью и универсальностью. С одной стороны, на SMP-машине должны существовать способы получить почти столь же высокую скорость при обмене данными между ветвями, как и при традиционном программировании через разделяемую память и семафоры. С другой стороны, все функции должны работать на любой платформе.
- проведение декомпозиции,
- запись ее в терминах MPI.
- ошибки, которые MPI в-принципе не может обнаружить в момент выполнения, генератор имеет возможность обнаруживать в момент построения программы, например:
Ветвь 1: Ветвь 2: MPI_Recv( ... , 2, ... ); MPI_Recv( ... , 1, ... ); MPI_Send( ... , 2, ... ); MPI_Send( ... , 1, ... ); | | Это номер ветви-отправителя/получателяПримечание: здесь произойдет блокировка - ветви не смогут завершить прием, потому что не смогут начать передачу, потому что не смогут завершить прием. Как итог, программа повиснет.Еще одно примечание: а вот если вызовы функций приема и передачи поменять местами, то блокировки не произойдет - MPI выберет для передачи буферизованный режим, и MPI_Send, скопировав данные во временный буфер, вернет управление сразу же, не дожидаясь, пока сообщение будет фактически принято приемной стороной. Таким образом, по сравнению с низкоуровневыми коммуникациями, MPI все-таки делает программу более устойчивой к ошибкам программиста. Правда, буферизация означает падение быстродействия тем более ощутимое, чем быстрее происходит собственно пересылка данных.
- некоторые ошибки исключаются вообще, например, одинаковый числовой идентификатор для разных сообщений, или неверный (больше общего количества ветвей в коллективе) номер ветви в аргументах функции приемопередачи - в отличие от человека, программа-генератор, если только она сама написана правильно, не в состоянии описАться.
Средства автоматической декомпозиции. Идеалом является такое оптимизирующее средство, которое на входе получает исходный текст некоего последовательного алгоритма, написанный на обычном языке программирования, и выдает на выходе исходный текст этого же алгоритма на этом же языке, но уже в распараллеленном на ветви виде, с вызовами MPI. Что ж, такие средства созданы (например, в состав полнофункционального пакета Forge входит, наряду с прочим, и такой препроцессор), но до сих пор, насколько мне известно, никто не торопится раздавать их бесплатно. Кроме того, вызывает сомнение их эффективность.
языки программирования. Это наиболее популярные на сегодняшний день средства полуавтоматической декомпозиции. В синтаксис универсального языка программирования (Си или Фортрана) вводятся дополнения для записи параллельных конструкций кода и данных. Препроцессор переводит текст в текст на стандартном языке с вызовами MPI. Примеры таких систем: mpC (massively parallel C) и HPF (High Performance Fortran).
Общим недостатком инструментов, производящих преобразование "текст в текст", является то, что синтаксическому разбору подвергаются оба текста: и исходный (его обрабатывает распараллеливающий препроцессор), и генерируемый (его обрабатывает компилятор). Это уменьшает скорость построения программы, и, кроме того, необходимость делать синтаксический разбор усложняет написание препроцессора. Поэтому, например, те фирмы-производители, которые поставляют свои ЭВМ вместе с Фортраном, встраивают HPF прямо в компилятор машинно-зависимого кода. Для расширений языка Си аналогичное решение может быть найдено в использовании GNU C.
Оптимизированные библиотеки для стандартных языков. В этом случае оптимизация вообще может быть скрыта от проблемного программиста. Чем больший объем работы внутри программы отводится подпрограммам такой библиотеки, тем бОльшим будет итоговый выигрыш в скорости ее (программы) работы. Собственно же программа пишется на обычном языке программирования безо всяких упоминаний об MPI, и строится стандартным компилятором. От программиста потребуется лишь указать для компоновки имя библиотечного файла MPI, и запускать полученный в итоге исполняемый не непосредственно, а через MPI-загрузчик. Популярные библиотеки обработки матриц, такие как Linpack, Lapack и ScaLapack, уже переписаны под MPI.
Средства визуального проектирования. Действительно, почему бы не расположить на экране несколько окон с исходным текстом ветвей, и пусть пользователь легким движением мыши протягивает стрелки от точек передачи к точкам приема - а визуальный построитель генерирует полный исходный текст? Тем, кто стряпал базы данных в Access'e, такая технология покажется наиболее естественной.
Отладчики и профайлеры. Об отладчиках мне пока нечего сказать, кроме того, что они нужны. Должна быть возможность одновременной трассировки/просмотра нескольких параллельно работающих ветвей - что-либо более конкретное мне пока сказать трудно.